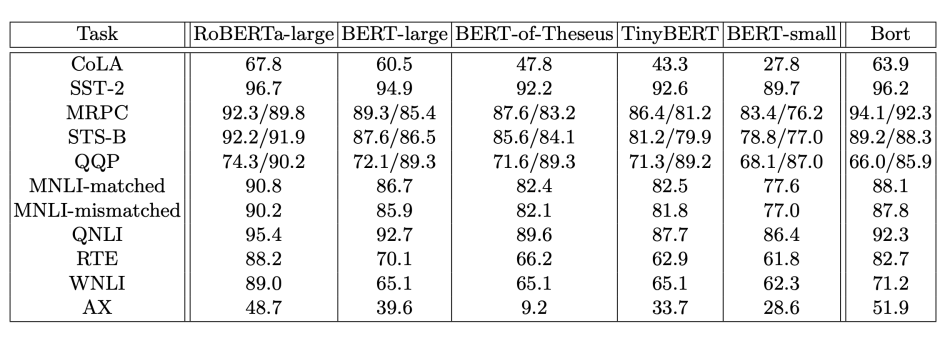

As a result, RoBERTa outperforms both BERT and XLNet on GLUE benchmark results: Performance comparison from RoBERTa. On the other hand, to reduce the computational (training, prediction) times of BERT or related models, a natural choice is to use a smaller network to approximate the performance.
Also, How is RoBERTa trained?
RoBERTa uses dynamic masking, with a new masking pattern generated each time a sentence is fed into training. … Finally, RoBERTa was trained using larger mini-batch sizes: 8K sequences compared to BERT’s 256.
Is there anything better than BERT?
Empirically, XLNet outperforms BERT on 20 tasks, often by a large margin, and achieves state-of-the-art results on 18 tasks including question answering, natural language inference, sentiment analysis, and document ranking.
Keeping this in consideration Which is the best language model?
Top 10 Pre-Trained NLP Language Models
- BERT (Bidirectional Encoder Representations from Transformers) BERT is a technique for NLP pre-training, developed by Google. …
- RoBERTa (Robustly Optimized BERT Pretraining Approach) …
- OpenAI’s GPT-3. …
- ALBERT. …
- XLNet.
What Tokenizer does RoBERTa use?
RoBERTa has the same architecture as BERT, but uses a byte-level BPE as a tokenizer (same as GPT-2) and uses a different pretraining scheme.
How does RoBERTa Tokenizer work?
GPT2, RoBERTa
BPE is a frequency-based character concatenating algorithm: it starts with two-byte characters as tokens and based on the frequency of n-gram token-pairs, it includes additional, longer tokens.
Is LSTM better than BERT?
As shown below, it naturally performed better as the number of input data increases and reach 75%+ score at around 100k data. BERT performed a little better than LSTM but no significant difference when the models are trained for the same amount of time.
Is BERT a transformer?
Bidirectional Encoder Representations from Transformers (BERT) is a transformer-based machine learning technique for natural language processing (NLP) pre-training developed by Google. BERT was created and published in 2018 by Jacob Devlin and his colleagues from Google.
Why is BERT the best?
1, BERT achieves 93.2% F1 score (a measure of accuracy), surpassing the previous state-of-the-art score of 91.6% and human-level score of 91.2%: BERT also improves the state-of-the-art by 7.6% absolute on the very challenging GLUE benchmark, a set of 9 diverse Natural Language Understanding (NLU) tasks.
What is GPT2 model?
Generative Pre-trained Transformer 2 (GPT-2) is an open-source artificial intelligence created by OpenAI in February 2019. … The GPT architecture implements a deep neural network, specifically a transformer model, which uses attention in place of previous recurrence- and convolution-based architectures.
What is RoBERTa?
RoBERTa stands for Robustly Optimized BERT Pre-training Approach. It was presented by researchers at Facebook and Washington University. The goal of this paper was to optimize the training of BERT architecture in order to take lesser time during pre-training.
Which NLP model gives best accuracy?
Naive Bayes is the most precise model, with a precision of 88.35%, whereas Decision Trees have a precision of 66%.
How do you pronounce RoBERTa?
Traditional IPA: rəˈbɜːtə 3 syllables: “ruh” + “BUR” + “tuh”
What’s a Tokenizer?
Tokenization is the process of removing sensitive data from your business systems by replacing it with an undecipherable token and storing the original data in a secure cloud data vault. Encrypted numbers can be decrypted with the appropriate key.
How many parameters does RoBERTa?
The DistilRoBERTa model distilled from the RoBERTa model roberta-base checkpoint. 12-layer, 768-hidden, 12-heads, 110M parameters.
What is a token in Transformers?
token: a part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords) or a punctuation symbol. transformer: self-attention based deep learning model architecture.
Does BERT uses LSTM?
Bidirectional LSTM is trained both from left-to-right to predict the next word, and right-to-left, to predict the previous word. … But, in BERT, the model is made to learn from words in all positions, meaning the entire sentence. Further, Google also used Transformers, which made the model even more accurate.
Why is LSTM better than RNN?
We can say that, when we move from RNN to LSTM, we are introducing more & more controlling knobs, which control the flow and mixing of Inputs as per trained Weights. And thus, bringing in more flexibility in controlling the outputs. So, LSTM gives us the most Control-ability and thus, Better Results.
Why Transformers are better than LSTM?
To summarise, Transformers are better than all the other architectures because they totally avoid recursion, by processing sentences as a whole and by learning relationships between words thank’s to multi-head attention mechanisms and positional embeddings.
What is difference between BERT and transformer?
Introduction to BERT
One of the difference is BERT use bidirectional transformer (both left-to-right and right-to-left direction) rather than dictional transformer (left-to-right direction). On the other hand, both ELMo use bidirectional language model to learn the text representations.
Why is BERT used?
BERT is designed to help computers understand the meaning of ambiguous language in text by using surrounding text to establish context. … Using this bidirectional capability, BERT is pre-trained on two different, but related, NLP tasks: Masked Language Modeling and Next Sentence Prediction.
What’s the difference between BERT and transformer?
BERT is only an encoder, while the original transformer is composed of an encoder and decoder. Given that BERT uses an encoder that is very similar to the original encoder of the transformer, we can say that BERT is a transformer-based model.
Is BERT deep learning?
BERT is described as a pre-trained deep learning natural language framework that has given state-of-the-art results on a wide variety of natural language processing tasks.
Is BERT better than ELMo?
Model Input
ELMo uses character based input and ULMFit is word based. It’s been claimed that character level language models don’t perform as well as word based ones but word based models have the issue of out-of-vocabulary words. BERT’s sub-words approach enjoys the best of both worlds.






